
مقدمه
در دههٔ اخیر، اینترنت اشیا (IoT) بهعنوان یک انقلاب دیجیتالی شناخته شده است که مرزهای سنتی بین دنیای فیزیکی و دیجیتال را محو میکند. میلیونها دستگاه هوشمند—از حسگرهای دما در یک کارخانه تا ساعتهای هوشمند در دست کاربران—بهصورت پیوسته دادهها را تولید، پردازش و بههم متصل میکنند. برای بهرهبرداری مؤثر از این حجم عظیم دادهها، زیرساختهای محاسباتی قدرتمند و مقیاسپذیر مورد نیاز است. این زیرساختها شامل سرورهای مجازی لینوکس، سرورهای مجازی ویندوز، سرورهای ابری و سرورهای اختصاصی میشوند که هر کدام نقش خاصی در اکوسیستم IoT ایفا میکنند.
۱. اینترنت اشیا (IoT) چیست؟
۱.۱ تعریف پایه
اینترنت اشیا بهمعنای شبکهای از اشیا (دستگاهها، حسگرها، ماشینآلات، ساختمانها و حتی پوشاک) است که با استفاده از حسگرها، نرمافزارها و ارتباطات بیسیم به یکدیگر و به اینترنت متصل میشوند. این اشیا میتوانند دادههای فیزیکی (دما، فشار، رطوبت، موقعیت جغرافیایی) را جمعآوری، پردازش و بهصورت خودکار یا تحت کنترل انسان به دیگر سیستمها ارسال کنند.
۱.۲ معماری لایهای
معماری رایج IoT بهصورت لایهای طراحی میشود تا پیچیدگی مدیریت دستگاهها، ارتباطات و پردازش دادهها کاهش یابد. این لایهها عبارتند از:
– لایه حسگر/اکچویتور: شامل تمام دستگاههای فیزیکی است که دادهها را جمعآوری یا عمل خاصی را انجام میدهند (مثلاً حسگر دما، رله کنترل روشنایی).
– لایه اتصال: مسئول انتقال دادهها از حسگرها به سرور یا گیتوی است. این لایه میتواند از فناوریهای مختلفی مانند Wi‑Fi، LoRaWAN، NB‑IoT، 5G یا حتی کابلکشی Ethernet استفاده کند.
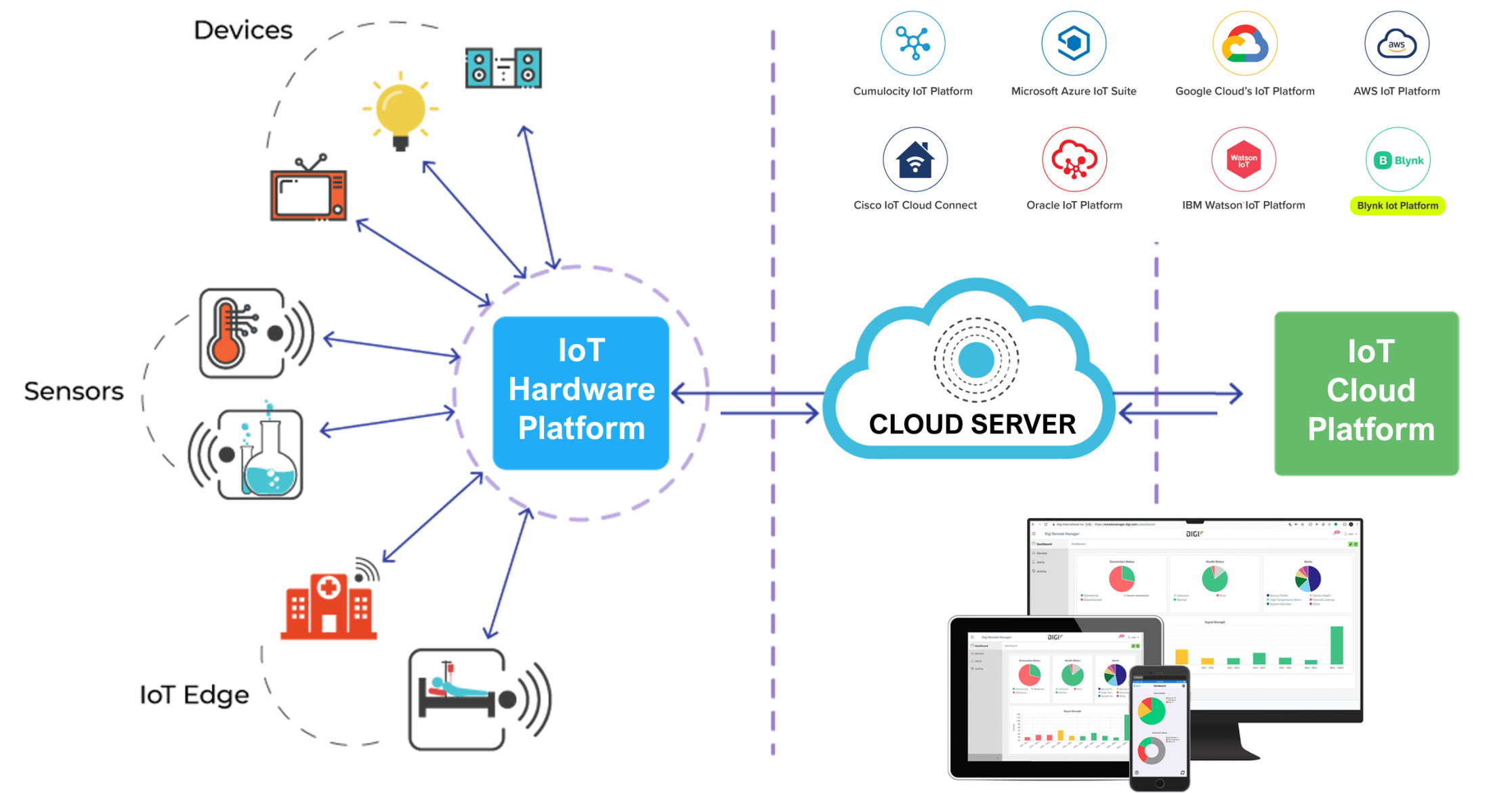
– لایه پردازش/پلتفرم: دادههای دریافتی در این لایه پردازش، تجزیه و تحلیل و ذخیره میشوند. پلتفرمهای ابری مانند AWS IoT Core، Azure IoT Hub یا Google Cloud IoT این وظیفه را بر عهده دارند.
– لایه اپلیکیشن: نتایج پردازش بهصورت سرویسهای نهایی به کاربر یا سیستمهای دیگر ارائه میشود؛ برای مثال داشبوردهای مانیتورینگ، سیستمهای خودکار تولید یا برنامههای موبایل.
۱.۳ چرا “ابر” در IoT مهم است؟
- مقیاسپذیری: حجم دادههای تولیدی توسط دستگاههای IoT میتواند به پتابایت برسد؛ سرورهای ابری میتوانند بهسرعت منابع محاسباتی را افزایش یا کاهش دهند.
- دسترسپذیری جهانی: سرویسهای ابری در مراکز داده در سرتاسر جهان توزیع شدهاند؛ بنابراین دادهها از هر نقطهای قابل دسترسی هستند.
- مدیریت ساده: بهجای مدیریت سختافزارهای فیزیکی، سازمانها میتوانند از سرویسهای مدیریتشده (Managed Services) استفاده کنند.
- هزینههای پیشبینیشده: مدلهای پرداخت بهازای استفاده (pay‑as‑you‑go) بهخصوص برای پروژههای آزمایشی یا فازهای اولیه مفید است.

۲. ابر اینترنت اشیا (IoT Cloud)
۲.۱ تعریف
ابر اینترنت اشیا ترکیبی از زیرساختهای ابری (سرورهای مجازی، سرویسهای ذخیرهسازی، پردازش توزیعی) و پلتفرمهای مدیریت IoT است که بهصورت یکپارچه امکان اتصال، مدیریت، تجزیه و تحلیل و یکپارچهسازی دادههای دستگاههای متصل را فراهم میکند. این ترکیب به سازمانها اجازه میدهد تا بدون نیاز به سرمایهگذاری سنگین در سختافزار، راهحلهای مقیاسپذیر و ایمن برای جمعآوری و پردازش دادههای زمان‑واقعی پیادهسازی کنند.
۲.۲ سرویسهای کلیدی در ابر IoT
در یک پلتفرم ابر IoT، سرویسهای زیر بهصورت معمولی در دسترس هستند:
– مدیریت دستگاه (Device Management): ثبت، پیکربندی، بهروزرسانی نرمافزار (OTA) دستگاهها. این سرویس بهصورت خودکار میتواند هزاران دستگاه را در زمان کوتاهی مدیریت کند.
– دریافت داده (Data Ingestion): جمعآوری دادههای زمان‑واقعی از دستگاهها با استفاده از پروتکلهای MQTT، HTTP یا CoAP.
– پردازش جریان (Stream Processing): پردازش لحظهای دادهها برای فیلتر، تجمیع یا تشخیص ناهنجاری. این کار معمولاً با توابع سرورلس (Serverless) یا سرویسهای پردازش جریان انجام میشود.
– ذخیرهسازی (Storage): ذخیرهسازی بلندمدت دادههای تاریخی در سرویسهای مقیاسپذیر مانند Amazon S3 یا Azure Blob Storage.
– تحلیل و هوش مصنوعی (Analytics & AI): تجزیه و تحلیل پیشرفته، پیشبینی، تشخیص ناهنجاری با استفاده از مدلهای یادگیری ماشین.
– امنیت و هویت (Security & Identity): احراز هویت دستگاه، رمزنگاری دادهها، مدیریت کلیدهای امنیتی.
۲.۳ مزایای استفاده از ابر IoT
– سرعت راهاندازی: با استفاده از سرویسهای مدیریتشده، میتوان در کمتر از یک هفته یک شبکه IoT کامل را راهاندازی کرد.
– قابلیت اطمینان بالا: مراکز دادهٔ بزرگ با SLAهای ۹۹٫۹۹٪ در دسترس بودن، تضمین میکنند که دادهها از دست نروند.
– یکپارچگی با سرویسهای دیگر: امکان اتصال به سرویسهای تحلیلی، BI، و حتی ERPها وجود دارد.
– امنیت پیشرفته: ارائهدهندگان ابری ابزارهای امنیتی یکپارچه (مانند IAM، KMS) برای محافظت از دادهها فراهم میکنند.
۳. انواع سرورهای مورد استفاده در اکوسیستم IoT
۳.۱ سرورهای مجازی لینوکس
۳.۱.۱ ویژگیها
– قابلیت سفارشیسازی بالا: میتوان توزیعهای مختلف لینوکس (Ubuntu, CentOS, Debian) را بر حسب نیاز نصب کرد.
– پشتیبانی از ابزارهای متنباز: Docker, Kubernetes, Mosquitto (سرور MQTT) و InfluxDB (پایگاه داده سری زمانی) بهراحتی قابل نصب هستند.
– هزینه نسبتاً پایین: در اکثر ارائهدهندگان ابری، سرورهای مجازی لینوکس بهعنوان گزینهٔ اقتصادی برای بارهای کاری متوسط تا بزرگ شناخته میشوند.
۳.۱.۲ کاربردها در IoT
– پلتفرمهای پردازش داده: اجرای سرویسهای پردازش جریان (Apache Flink, Spark Streaming) برای تجزیه و تحلیل دادههای زمان‑واقعی.
– پایگاه دادههای سری زمانی: ذخیرهسازی دادههای حسگر در InfluxDB یا TimescaleDB برای تجزیه و تحلیل تاریخی.
– سرورهای MQTT: میزبانی Mosquitto یا EMQX برای ارتباطات دستگاه‑به‑سرور (Device‑to‑Server).
۳.۱.۳ نکات فنی مهم
– پیکربندی شبکه: استفاده از VPC (Virtual Private Cloud) برای جداسازی ترافیک IoT از سایر سرویسها.
– امنیت: فعالسازی فایروالهای سطحپروتکل (Security Groups) و استفاده از TLS برای ارتباطات MQTT.
– مقیاسپذیری: تنظیم Auto‑Scaling Group برای افزودن یا حذف سرورهای مجازی بر اساس بار پردازشی.
۳.۲ سرورهای مجازی ویندوز
۳.۲.۱ ویژگیها
– پشتیبانی از نرمافزارهای تجاری ویندوزی: بسیاری از برنامههای صنعتی (مانند SCADA، نرمافزارهای PLC) فقط بر روی سیستمعامل ویندوز اجرا میشوند.
– یکپارچگی با Active Directory: امکان استفاده از سرویسهای دایرکتوری برای مدیریت هویت دستگاهها و کاربران.
– پشتیبانی از .NET و PowerShell: توسعه سریع سرویسهای سفارشی برای جمعآوری و پردازش دادههای IoT.
۳.۲.۲ کاربردها در IoT
– پلتفرمهای مدیریت دستگاه ویندوزی: اجرای Azure IoT Edge یا AWS Greengrass بر روی ویندوز برای پردازش محلی (Edge Computing).
– پایگاه دادههای رابطهای: استفاده از Microsoft SQL Server برای ذخیرهسازی دادههای ساختاریافته و گزارشگیری تجاری.
– یکپارچهسازی با سیستمهای ERP/CRM: اتصال مستقیم به Microsoft Dynamics 365 یا SAP برای بهروزرسانی موجودی، سفارشات و سایر فرآیندهای کسبوکار.
۳.۲.۳ نکات فنی مهم
– پروتکلهای امنیتی: فعالسازی TLS/SSL برای تمام ارتباطات، بهویژه برای سرویسهای OPC-UA که در صنایع خودروسازی و انرژی رایج هستند.
– بهروزرسانی خودکار: استفاده از Windows Update Services (WSUS) یا Azure Update Management برای اطمینان از بهروز بودن سرورها.
– مقیاسپذیری: بهرهگیری از Azure Virtual Machine Scale Sets یا AWS Auto Scaling برای افزودن نمونههای ویندوزی بر حسب نیاز.
۳.۳ سرورهای ابری (Cloud Servers)
۳.۳.۱ تعریف
سرورهای ابری بهصورت منابع مجازیسازیشده در مراکز دادهٔ ارائهدهندگان ابری (AWS, Azure, Google Cloud) ارائه میشوند. این سرورها میتوانند بهسرعت ایجاد، حذف یا تغییر پیکربندی شوند و بهصورت خودکار با ابزارهای مدیریت زیرساخت (Infrastructure‑as‑Code) هماهنگ میشوند.
۳.۳.۲ مزایای کلیدی برای IoT
– Elasticity (قابلیت کشش): توان پردازشی میتواند در ثانیهها از چند CPU به صدها CPU افزایش یابد؛ این ویژگی برای پردازش ناگهانی حجم دادههای حسگرهای صنعتی حیاتی است.
– Managed Services: سرویسهای مدیریتشده مانند Amazon Kinesis, Azure Event Hubs یا Google Pub/Sub بهصورت آماده برای دریافت و پردازش جریان دادهها فراهم میشوند.
– Global Distribution: با استفاده از مناطق (Regions) و مناطق حاشیهای (Edge Locations) میتوان دادهها را نزدیک به منبع فیزیکی ذخیره و پردازش کرد، که تأخیر را به حداقل میرساند.
۳.۳.۳ معماری پیشنهادی برای یک راهحل IoT کامل
- Device Layer: حسگرها با استفاده از MQTT یا HTTPS به AWS IoT Core متصل میشوند.
- Ingestion Layer: پیامهای MQTT به Amazon Kinesis Data Streams یا AWS Lambda هدایت میشوند.
- Processing Layer: دادههای جریان توسط AWS Lambda یا AWS Glue پردازش میشوند؛ نتایج به Amazon DynamoDB (کلید‑مقدار) یا Amazon S3 (ذخیرهسازی طولانیمدت) ارسال میشوند.
- Analytics Layer: با استفاده از Amazon QuickSight یا AWS SageMaker داشبوردهای زمان‑واقعی و مدلهای پیشبینی ساخته میشود.
- Security Layer: تمام ارتباطات با TLS 1.2 رمزنگاری میشوند؛ هویت دستگاهها با AWS IoT Device Defender مدیریت میشود.
۳.۳.۴ نکات عملی برای پیادهسازی
– استفاده از VPC Endpoints: برای جلوگیری از عبور دادههای حساس از اینترنت عمومی، از VPC Endpoints برای دسترسی به سرویسهای S3 و DynamoDB استفاده کنید.
– پیکربندی IAM نقشها: هر سرویس (مثلاً Lambda) باید فقط دسترسیهای لازم (Principle of Least Privilege) داشته باشد.
– مانیتورینگ: فعالسازی CloudWatch Metrics و Alarms برای نظارت بر نرخ خطاهای MQTT، زمان پردازش Lambda و مصرف ذخیرهسازی S3.

۳.۴ سرورهای اختصاصی (Dedicated Servers)
۳.۴.۱ تعریف
سرورهای اختصاصی بهمعنای سختافزار فیزیکی هستند که بهصورت کامل به یک مشتری اختصاص مییابند. این سرورها معمولاً در دیتاسنترهای محلی یا بهصورت colocation مستقر میشوند و کنترل کامل بر سختافزار، شبکه و سیستمعامل را فراهم میکنند.
۳.۴.۲ مزایای استفاده در محیطهای حساس
– کنترل کامل بر سختافزار: امکان استفاده از کارتهای شبکه با سرعت ۱۰ Gbps یا NVMe SSDهای با عملکرد بالا برای پردازش دادههای زمان‑واقعی.
– انطباق با استانداردهای امنیتی: برخی صنایع (مانند انرژی، نظامی) نیاز به رعایت استانداردهای سختافزاری خاص (FIPS 140‑2، ISO 27001) دارند که سرورهای اختصاصی میتوانند این الزامات را برآورده کنند.
– پایداری شبکه: با داشتن مسیرهای فیزیکی جداگانه میتوان از تداخل ترافیک عمومی جلوگیری کرد.
۳.۴.۳ کاربردهای رایج در IoT
– پلتفرمهای Edge Computing: اجرای نرمافزارهای پردازش محلی (مثل NVIDIA Jetson یا Intel OpenVINO) بر روی سرورهای اختصاصی نزدیک به حسگرها برای کاهش تأخیر.
– پایگاه دادههای بزرگ: استفاده از ClickHouse یا Apache Cassandra بر روی سرورهای اختصاصی برای ذخیرهسازی مقادیر بزرگ دادههای سری زمانی با عملکرد بالا.
– سیستمهای زمان‑حقیقی (RTOS) ترکیبی: ترکیب سرورهای اختصاصی با نرمافزارهای زمان‑حقیقی برای کنترل فرآیندهای صنعتی حساس (مانند خطوط تولید خودکار).
۳.۴.۴ نکات فنی مهم
– پیکربندی RAID: برای اطمینان از تحمل خطا و دسترسی سریع به دادهها، از RAID 10 یا RAID 6 استفاده کنید.
– پروتکلهای صنعتی: پشتیبانی از پروتکلهای OPC‑UA، Modbus TCP یا EtherCAT برای ارتباط مستقیم با PLCها و دستگاههای صنعتی.
– پروکسی و فایروال سختافزاری: برای جداسازی شبکهٔ IoT از شبکهٔ اداری، از فایروالهای لایهٔ ۳/۴ (مثل Palo Alto یا Fortinet) استفاده کنید.
۴. ترکیب انواع سرورها در یک معماری مقیاسپذیر IoT
۴.۱ الگوی ترکیبی (Hybrid Architecture)
در بسیاری از پروژههای بزرگ، استفادهٔ صرف از یک نوع سرور (مثلاً فقط سرورهای ابری) کافی نیست. ترکیب سرورهای مجازی لینوکس، سرورهای مجازی ویندوز، سرورهای ابری و سرورهای اختصاصی بهصورت لایهای، امکان بهرهبرداری از مزایای هر کدام را فراهم میکند. یک الگوی ترکیبی معمولاً به این شکل است:
- لایه Edge (سرورهای اختصاصی): نزدیک به حسگرها، پردازش اولیه (فیلتر، تجمیع) و اجرای الگوریتمهای هوش مصنوعی سبک.
- لایه Aggregation (سرورهای مجازی لینوکس): دریافت دادههای فشردهشده از لایه Edge، ذخیرهسازی موقت در InfluxDB و ارسال به لایه Cloud.
- لایه Cloud (سرورهای ابری): پردازش جریان، تجزیه و تحلیل پیشرفته، یادگیری ماشین و ارائه داشبوردهای زمان‑واقعی.
- لایه Enterprise (سرورهای مجازی ویندوز): یکپارچهسازی با سیستمهای ERP/CRM، گزارشگیری تجاری و مدیریت هویت با Active Directory.
۴.۲ مزایای این ترکیب
– بهینهسازی هزینه: پردازش سنگین در لایه Cloud انجام میشود، در حالی که پردازشهای زمان‑حقیقی در لایه Edge (سرورهای اختصاصی) انجام میشود؛ این ترکیب هزینهٔ پهنای باند و ذخیرهسازی را کاهش میدهد.
– قابلیت تحمل خطا: اگر یک لایه (مثلاً سرورهای ابری) دچار اختلال شود.
، دادههای مهم در لایه Edge و Aggregation همچنان در دسترس هستند و میتوانند بهصورت موقت بهکارگیری شوند تا پس از بازیابی سرویسهای ابری، همگامسازی انجام گیرد.
– بهبود امنیت: با جداسازی شبکههای Edge و Cloud، دسترسی مستقیم به دادههای حساس محدود میشود؛ فقط دادههای فشردهشده و غیرحساس بهصورت رمزنگاریشده بهسرورهای ابری ارسال میشود.
– پایداری عملکرد: سرورهای اختصاصی میتوانند با پردازش زمان‑حقیقی (مانند کنترل روباتیک یا سیستمهای حفاظتی) بدون تأخیر شبکهای عمل کنند، در حالی که تجزیه و تحلیلهای سنگین در بستر ابری انجام میشود.
۵. مثال عملی: پیادهسازی یک سامانهٔ هوشمند کشاورزی
۵.۱ سناریو
یک مزرعهٔ هوشمند میخواهد دما، رطوبت خاک، نور و سطح آبپاشی را بهصورت زمان‑واقعی مانیتور کند و بر اساس پیشبینیهای هوایی، سیستمهای آبیاری را بهصورت خودکار تنظیم نماید.
۵.۲ معماری پیشنهادی
لایهٔ Edge (سرور اختصاصی)
– فناوری: NVIDIA Jetson Nano بههمراه سیستمعامل Ubuntu Server.
– نقش: این دستگاه در محل فیزیکی مزرعه مستقر میشود و مستقیماً به حسگرهای محیطی (دما، رطوبت خاک، نور، فشار هوا) متصل میشود. دادههای خام را دریافت میکند، فیلتر نویز انجام میدهد و بهصورت محلی پیشپردازش میکند. برای پیشبینی بارش، یک مدل یادگیری عمیق بهصورت بهینهسازی شده با TensorRT روی Jetson اجرا میشود؛ این کار باعث میشود پیشبینیها در زمان واقعی و با تأخیر بسیار کم (کمتر از چند میلیثانیه) انجام شوند.
لایهٔ Aggregation (سرور مجازی لینوکس)
– فناوری: یک ماشین مجازی Amazon EC2 از نوع t3.medium که با Docker اجرا میشود؛ داخل آن سرویس Mosquitto MQTT مستقر است.
– نقش: سرور Edge پیامهای MQTT را به این سرور میفرستد. Mosquitto بهعنوان یک بروکر سبک وزن، پیامها را دریافت، صفبندی و بهسرورهای دیگر تحویل میدهد. برای ذخیرهسازی موقت دادههای زمان‑واقعی، یک پایگاه داده سری‑زمانی InfluxDB در همان Docker container راهاندازی میشود؛ این پایگاه امکان کوئری سریع برای نمایش وضعیت جاری در داشبوردهای محلی را فراهم میکند. پس از ذخیرهسازی موقت، دادهها به سرویس Kinesis Data Streams در ابر ارسال میشوند تا جریان پردازش ادامه یابد.
لایهٔ Cloud (سرور ابری)
– فناوری: ترکیبی از AWS Lambda (توابع سرورلس)، Kinesis Data Streams (جمعآوری جریان داده) و SageMaker (پلتفرم یادگیری ماشین).
– نقش: Kinesis بهصورت پیوسته دادههای حسگر را به Lambda میفرستد. هر بار که یک بسته داده میرسد، Lambda آن را پردازش میکند (مثلاً تبدیل واحدها، حذف مقادیر نادرست) و سپس به یک مدل پیشبینی در SageMaker میفرستد. مدل پیشبینی نیاز آبیاری بر اساس دادههای محیطی و پیشبینی بارش را محاسبه میکند. نتایج پیشبینی (مثلاً مقدار آب مورد نیاز برای هر بخش از مزرعه) در DynamoDB ذخیره میشود؛ این دیتابیس کلید‑مقدار بهسرعت قابل جستجو برای برنامههای دیگر است.
لایهٔ Enterprise (سرور مجازی ویندوز)
– فناوری: یک ماشین مجازی Azure Virtual Machine از نوع Standard_D2s_v3 که بر روی آن SQL Server نصب شده است.
– نقش: این لایه بهعنوان پل بین دادههای فنی IoT و سیستمهای تجاری مزرعه عمل میکند. دادههای پیشبینی شده در DynamoDB توسط یک سرویس میانی (مثلاً Azure Function یا یک برنامه .NET) به SQL Server منتقل میشوند. در SQL Server، این دادهها با اطلاعات موجودی بذر، کود و برنامههای تولید ترکیب میشوند؛ به این ترتیب ERP مزرعه میتواند برنامهریزی دقیقتری برای خرید مواد، زمانبندی کاشت و گزارشگیری به مدیران ارائه دهد. داشبوردهای Power BI یا سایر ابزارهای BI به این دیتابیس متصل میشوند و گزارشهای گرافیکی زمان‑واقعی درباره وضعیت آبیاری، پیشبینی بارش و مصرف منابع را نمایش میدهند.
بهطور خلاصه، این معماری از لبه به سمت ابر بهصورت سلسلهمراتبی دادهها را جمعآوری، پیشپردازش، تجزیه و تحلیل میکند و در نهایت نتایج را به سامانههای تجاری (ERP) متصل میسازد تا تصمیمگیریهای هوشمندانه و خودکار در مزرعه امکانپذیر شود.
۵.۳ جریان داده
- حسگرها هر ۱۰ ثانیه دادههای خود را به Mosquitto در لایه Aggregation ارسال میکنند.
- Mosquitto پیامها را به Kinesis میفرستد؛ در همان زمان، دادهها در InfluxDB برای مانیتورینگ محلی ذخیره میشوند.
- AWS Lambda بهصورت batch هر ۳۰ ثانیه دادهها را از Kinesis میخواند، پیشپردازش میکند و به SageMaker Endpoint برای پیشبینی بارش میفرستد.
- نتایج پیشبینی (مثلاً “بارش ۲۲ % در ۲ ساعت آینده”) در DynamoDB ذخیره میشود.
- یک Azure Function (بهعنوان پل) نتایج را به SQL Server در لایه Enterprise میکشد؛ این دادهها در داشبورد Power BI برای مدیران نمایش داده میشود.
- در صورت پیشبینی بارش، Edge با دریافت فرمان از Lambda (از طریق MQTT) سیستم آبیاری را خاموش میکند.
۵.۴ نکات امنیتی
– تمام ارتباطات MQTT با TLS 1.3 رمزنگاری میشوند.
– کلیدهای خصوصی در AWS KMS ذخیره و مدیریت میشوند؛ دسترسی به آنها فقط برای نقش IAM “IoTDeviceManager” مجاز است.
– در لایه Edge، فایروال سختافزاری Fortinet فقط پورتهای ۸۸۳۳ (MQTT) و ۲۲ (SSH) را باز میکند.
۶. بهترین شیوهها برای مدیریت زیرساختهای IoT
- Infrastructure‑as‑Code (IaC): از ابزارهایی مانند Terraformیا AWS CloudFormation برای تعریف تمام منابع (VPC، EC2، RDS، IAM) استفاده کنید؛ این کار باعث میشود زیرساخت قابل تکرار و نسخهبندی شود.
- Monitoring & Alerting: ترکیب CloudWatch, Prometheus و Grafana برای نظارت بر متریکهای کلیدی (latency MQTT, CPU usage, storage I/O) و تنظیم آلارمهای خودکار.
- Log Centralization: تمام لاگهای دستگاهها، سرورها و سرویسهای ابری را به Elastic Stackیا AWS OpenSearch ارسال کنید؛ این کار برای تشخیص نفوذ و دیباگ ضروری است.
- Security‑by‑Design:
– استفاده از mutual TLS برای احراز هویت دستگاهها.
– اعمال principle of least privilege در IAM.
– بهروزرسانی منظم سیستمعاملها (patch management) بهخصوص در سرورهای ویندوز.
- Cost Optimization:
– استفاده از Reserved Instances یا Savings Plans برای سرورهای ثابت.
– فعالسازی Auto‑Scaling برای سرورهای مجازی لینوکس در زمانهای اوج بار.
– حذف منابع غیرفعال (مثلاً EBS volumes بدون استفاده) بهصورت دورهای.
۷. چالشهای رایج و راهحلها
پهنای باند محدود یکی از مهمترین موانع در پیادهسازی پروژههای اینترنت اشیا بهویژه در مناطق روستایی یا کارخانجات صنعتی است که زیرساختهای ارتباطی ناپایدار یا با ظرفیت کم دارند. برای مقابله با این مشکل، معمولاً پردازش اولیه دادهها در لایهٔ لبه (Edge) انجام میشود؛ حسگرها دادههای خام را بهسرورهای لبه میفرستند، در آنجا دادهها فشرده، فیلتر و بهصورت خلاصهسازی شده (مثلاً فقط مقادیر بحرانی یا تغییرات بزرگ) به ابر ارسال میشوند. این کار نهتنها حجم ترافیک را بهطور چشمگیری کاهش میدهد، بلکه زمان واکنش سیستم را نیز بهبود میبخشد.
تأخیر (Latency) برای برخی برنامههای حساس—مانند کنترل روباتیک، سامانههای حفاظتی یا سیستمهای زمان‑حقیقی در خطوط تولید—باید زیر صد میلیثانیه باشد. برای رسیدن به این هدف، سرورهای اختصاصی یا دستگاههای لبه که بهصورت فیزیکی نزدیک به حسگرها قرار دارند، استفاده میشوند. علاوه بر این، انتخاب پروتکلهای سبک و بهینه مانند CoAP (Constrained Application Protocol) یا MQTT‑SN (MQTT for Sensor Networks) که سربار کمتری دارند، بهطور قابل توجهی زمان انتقال داده را کاهش میدهد.
مدیریت مقیاس بزرگ، بهویژه زمانی که تعداد دستگاهها به هزاران یا حتی میلیونها میرسد، میتواند فرآیند ثبت، پیکربندی و بهروزرسانی را پیچیده کند. راهحل معمول این است که از سرویسهای خودکار Provisioning استفاده شود؛ برای مثال AWS IoT Core یا Azure Device Provisioning Service (DPS) امکان ثبت خودکار دستگاهها، توزیع گواهینامههای امنیتی و اعمال تنظیمات پیشفرض را فراهم میکنند. این سرویسها بهصورت برنامهنویسیپذیر (API) قابل یکپارچهسازی هستند و میتوانند بهسرعت هزاران دستگاه را در زمان کوتاهی فعال کنند.
امنیت دادهها در محیطهای IoT بسیار حساس است؛ دادههای حسگر میتوانند شامل اطلاعات صنعتی، پزشکی یا شخصی باشند و در صورت دسترسی غیرمجاز، خطر جدی ایجاد میشود. برای محافظت از این دادهها، رمزنگاری انتها‑به‑انتها (TLS) در تمام مسیرهای ارتباطی الزامی است. علاوه بر این، ابزارهای نظارتی مانند AWS IoT Device Defender میتوانند رفتار دستگاهها را بهصورت مستمر بررسی کنند؛ هرگونه الگوی غیرعادی (مثلاً ارسال دادههای ناخواسته یا تلاش برای اتصال به سرویسهای غیرمجاز) بهسرعت شناسایی و هشدار میشود.
قابلیت اطمینان سرویسهای ابری نیز یک نگرانی اساسی است؛ قطع یا اختلال در سرویسهای ابری میتواند عملیات کل سامانه را متوقف کند. برای کاهش این ریسک، معماریهای چندمنطقهای (Multi‑Region) و فعال‑غیرفعال (Active‑Passive) طراحی میشوند. در این مدل، دادهها بهصورت همزمان در دو یا چند منطقه جغرافیایی ذخیره میشوند و در صورت بروز مشکل در یکی از مناطق، دیگر مناطق بهصورت خودکار بار کاری را بر عهده میگیرند. علاوه بر این، مکانیزمهای همگامسازی Edge‑to‑Cloud (مانند ذخیرهسازی محلی موقت در لبه) تضمین میکند که دادههای حیاتی حتی در زمان قطع ارتباط با ابر، در دستگاههای لبه نگهداری میشوند و پس از بازگشت اتصال، بهسرعت همگامسازی میشوند.
۸. آیندهٔ ابر اینترنت اشیا
- پلتفرمهای ترکیبی Edge‑Cloud: با پیشرفت فناوریهای 5G و MEC (Multi‑Access Edge Computing)، پردازشهای هوش مصنوعی بهصورت توزیعی بین لبه و ابر انجام میشود؛ این امر تأخیر را به زیر ۱۰ ms میرساند.
- استانداردهای باز: پروژههای OpenTelemetry و OpenIoT بهسرعت در حال گسترش هستند و امکان نظارت و متریکگیری یکنواخت در تمام لایهها را فراهم میکنند.
- حاکمیت دادهها (Data Sovereignty): قوانین جدید در اتحادیه اروپا و ایالات متحده، نیاز به ذخیرهسازی دادههای حساس در مرزهای جغرافیایی خاص دارند؛ این موضوع باعث رشد سرویسهای Local‑Region Cloud میشود.
- یکپارچهسازی با دیجیتال تو twins: مدلهای دیجیتال تو twins برای کارخانهها و شهرهای هوشمند، بهسرعت در حال پذیرش هستند؛ این مدلها نیاز به ترکیب دادههای زمان‑واقعی (از IoT) و شبیهسازیهای پیشرفته (در ابر) دارند.
۹. جمعبندی کلیدی
– IoT یک اکوسیستم لایهای است که برای عملکرد بهینه به زیرساختهای مقیاسپذیر نیاز دارد.
– ابر اینترنت اشیا با ترکیب سرویسهای مدیریت دستگاه، دریافت داده، پردازش جریان، ذخیرهسازی و تحلیل، امکان پیادهسازی سریع و ایمن را فراهم میکند.
– سرورهای مجازی لینوکس برای پردازش داده، پایگاههای سری زمانی و سرویسهای MQTT مناسباند؛ سرورهای مجازی ویندوز برای یکپارچهسازی با سیستمهای تجاری و نرمافزارهای صنعتی ویندوزی.
– سرورهای ابری مقیاسپذیری و سرویسهای مدیریتشده را ارائه میدهند


قوانین ارسال دیدگاه
لطفاً در ارسال دیدگاه از کلمات مناسب استفاده کنید. ارسال اسپم ممنوع است.