
مقدمه
در دنیای دیجیتال امروز، سئو بهعنوان ستون اصلی جذب ترافیک ارگانیک برای هر وبسایت شناخته میشود. با این حال، برخی تکنیکهای مخفی مانند Cloaking که بهدنبال فریب الگوریتمهای موتورهای جستجو هستند، میتوانند در کوتاهمدت نتایج جذابی بدهند اما بهسرعت منجر به جریمههای جدی، حذف از نتایج و حتی پیامدهای قانونی میشوند.
بهمنظور حفظ رتبههای پایدار و جلوگیری از خطرات احتمالی، تمرکز بر روشهای شفاف، بهینهسازی محتوا و تجربه کاربری است. این مقاله بهصورت جامع به بررسی پیامدهای قانونی و جریمههای موتورهای جستجو میپردازد و نکات کلیدی برای حفظ سئو سالم در طولانیمدت را ارائه میدهد.
۱. تعریف دقیق Cloaking
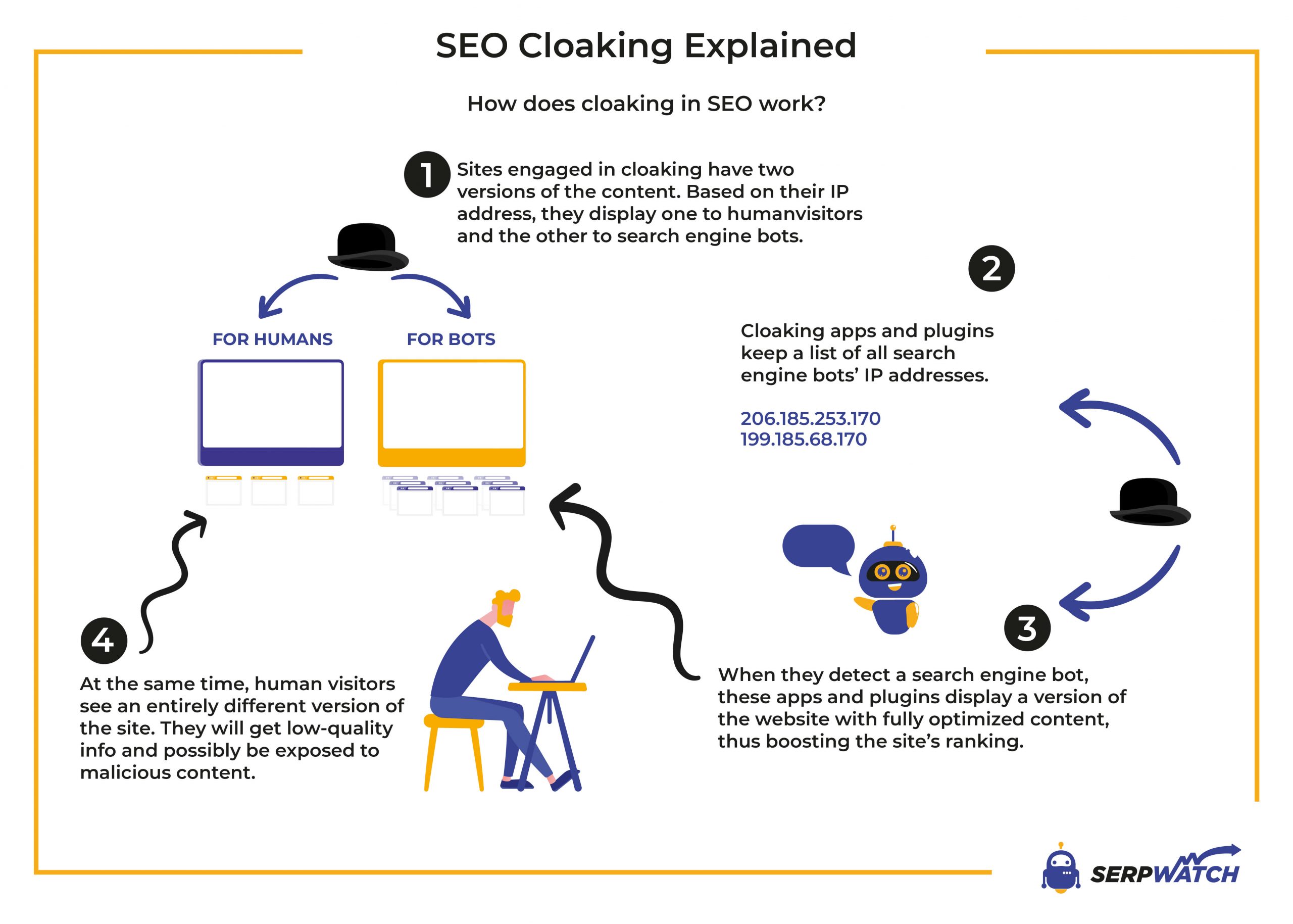
Cloaking به معنای «پوشاندن» یا «پنهانسازی» است و در سئو به عملی اطلاق میشود که در آن محتوا یا URL متفاوتی به موتورهای جستجو (رباتها) و به کاربران انسانی نمایش داده میشود. هدف اصلی این کار، فریب الگوریتمهای موتورهای جستجو برای ارتقای رتبهٔ صفحه است، در حالی که بازدیدکنندگان انسانی محتوای دیگری میبینند.
بهعبارت دیگر، اگر یک ربات گوگل درخواست یک صفحهٔ خاص را بفرستد، سرور تشخیص میدهد که درخواست از ربات است و محتوای بهینهشدهٔ SEO (متنهای پرکلید، لینکهای مخفی، یا حتی محتوای کاملاً متفاوت) را برمیگرداند؛ در حالی که همان URL برای کاربر واقعی، محتوای عادی یا حتی صفحهای کاملاً متفاوت (مثلاً صفحهٔ تبلیغاتی) نشان میدهد.

۲. تاریخچه و پیشزمینه
Cloaking از زمان پیدایش موتورهای جستجو وجود داشته است. در اوایل دههٔ ۲۰۰۰، برخی وبسایتها برای دور زدن محدودیتهای الگوریتمهای اولیه، محتوای متنی غنی را فقط به رباتها میدادند و به کاربران صفحهای ساده یا حتی صفحهٔ خطای 404 نشان میدادند. با پیشرفت الگوریتمهای گوگل (مانند Panda و Penguin) و افزایش توانایی تشخیص رفتارهای غیرطبیعی، این روش بهسرعت بهعنوان تخلف شناخته شد و جریمههای سنگینی برای سایتهای متخلف اعمال شد.
۳. چرا Cloaking ممنوع است؟
- نقض شفافیت – موتورهای جستجو بر پایهٔ اصل «کاربران و رباتها باید همان محتوا را ببینند» عمل میکنند. ارائهٔ محتوای متفاوت، فریبکارانه است.
- تجربهٔ کاربری مخدوش – کاربر انسانی ممکن است پس از کلیک بر روی نتایج جستجو، به صفحهای متفاوت از آنچه انتظار داشته است برسد؛ این باعث افزایش نرخ پرش (bounce rate) و کاهش رضایت میشود.
- آسیب به اعتبار دامنه – جریمههای الگوریتمی میتوانند بهصورت penalty یا de-indexing (حذف کامل از فهرست نتایج) اعمال شوند؛ بازگرداندن اعتبار پس از این جریمهها هزینهبر و زمانبر است.
بهدلیل این دلایل، Google’s Webmaster Guidelines بهوضوح میگوید: *«هر گونه نمایش محتوای متفاوت به رباتها و کاربران انسانی ممنوع است»*.
۴. انواع Cloaking
در ادامه، بهتفصیل هر یک از روشهای رایج Cloaking میپردازیم.
۴.۱. IP‑Based Cloaking
– نحوه کار: سرور IP کاربر را شناسایی میکند. اگر IP متعلق به رباتهای گوگل (مثلاً 66.249.*) باشد، محتوای بهینهشده را میفرستد؛ در غیر اینصورت، صفحهٔ دیگری نمایش میدهد.
– مزایا: نسبتاً ساده برای پیادهسازی با استفاده از قوانین .htaccess یا اسکریپتهای سرور.
– معایب: رباتهای پیشرفته میتوانند IP واقعی را مخفی کنند (با استفاده از VPN یا پراکسی)؛ همچنین، اگر ربات گوگل از IP جدیدی استفاده کند، این روش کار نمیکند.
۴.۲. User‑Agent Cloaking
– نحوه کار: مرورگر یا ربات در هدر HTTP یک رشتهٔ *User‑Agent* میفرستد (مثلاً `Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)`). سرور این رشته را بررسی میکند و بسته به آن محتوای متفاوتی میفرستد.
– مزایا: پیادهسازی ساده با استفاده از توابع `$_SERVER[‘HTTP_USER_AGENT’]` در PHP یا معادل در سایر زبانها.
– معایب: رباتهای پیشرفته میتوانند *User‑Agent* را تقلبی (spoof) کنند؛ همچنین، برخی مرورگرهای واقعی ممکن است بهصورت پیشفرض *User‑Agent* مشابه رباتها داشته باشند (مانند برخی مرورگرهای موبایل).
۴.۳. JavaScript / CSS Cloaking
– نحوه کار: با استفاده از اسکریپتهای JavaScript یا استایلهای CSS، محتوا برای رباتها (که معمولاً JavaScript را اجرا نمیکنند) مخفی میشود، در حالی که برای مرورگرهای کاربر نمایش داده میشود.
– مثال: `<noscript>` برای رباتها، یا `display:none` برای عناصر خاص که فقط توسط ربات خوانده میشوند.
– معایب: موتورهای مدرن (مانند Googlebot) اکنون JavaScript را اجرا میکنند؛ بنابراین این روش کمتر مؤثر است و بهسرعت شناسایی میشود.
۴.۴. Redirect Cloaking
– نحوه کار: سرور بر اساس تشخیص ربات یا کاربر، بهصورت 301/302 یا حتی 307 به URL دیگری هدایت میکند. برای رباتها، URL هدف بهینهشده است؛ برای کاربر، URL دیگری (مثلاً صفحهٔ فروش یا تبلیغاتی).
– معایب: رباتهای پیشرفته میتوانند ریدایرکتها را دنبال کنند و تشخیص دهند؛ همچنین، ریدایرکتهای بیش از حد میتوانند بهعنوان «doorway» شناخته شوند و جریمه شوند.
۴.۵. Server‑Side Includes (SSI) و Conditional Statements
– نحوه کار: با استفاده از SSI یا زبانهای برنامهنویسی سرور (PHP, ASP.NET, Node.js) شرطی برای نمایش محتوا بر اساس متغیرهای محیطی (مانند `$_SERVER[‘REMOTE_ADDR’]` یا `$_SERVER[‘HTTP_USER_AGENT’]`) تعریف میشود.
– معایب: همانند روشهای قبلی، اگر متغیرها بهدرستی شناسایی نشوند، رباتها میتوانند محتوای اصلی را ببینند و تشخیص تخلف را بدهند.

۵. ابزارهای تشخیص Cloaking
اگر میخواهید وبسایت خود یا رقبایتان را برای Cloaking بررسی کنید، ابزارهای زیر میتوانند مفید باشند:
- Google Search Console – URL Inspection
– با وارد کردن URL، میتوانید ببینید گوگل چه محتوایی را دریافت کرده است. اگر محتوای نمایش داده شده برای کاربر متفاوت باشد، این ابزار هشدار میدهد.
- Crawl Simulators (مثل Screaming Frog, Sitebulb)
– این ابزارها میتوانند درخواستها را با *User‑Agent*های مختلف (Googlebot, Bingbot, مرورگرهای عادی) بفرستند و خروجی را مقایسه کنند.
- Online Cloaking Checkers
– سرویسهای آنلاین مانند SEO Site Checkup یا Ahrefs Site Audit قابلیت مقایسهٔ محتوای ربات و کاربر را دارند.
- Manual Testing
– با استفاده از ابزارهای مرورگر (مانند Chrome DevTools) میتوانید هدرهای HTTP را تغییر دهید و ببینید سرور چه پاسخی میدهد.
- Log File Analysis
– بررسی لاگهای سرور (access logs) برای تشخیص الگوهای IP یا User‑Agent خاص که بهصورت مکرر به URLهای خاص دسترسی دارند.
۶. پیامدهای قانونی و جریمههای موتورهای جستجو
۶.۱. جریمههای الگوریتمی
Manual Action – Cloaking
تیم وبمستران گوگل پس از دریافت گزارش یا کشف خودکار تخلف، یک اقدام دستی (Manual Action) اعمال میکند. این اقدام میتواند به حذف کل دامنه یا حذف صفحات خاص از نتایج جستجو منجر شود. برای رفع این جریمه، تمام موارد تخلف باید حذف و اصلاح شوند؛ سپس با ارسال درخواست بازنگری (Reconsideration Request) ممکن است چند هفته تا چند ماه زمان ببرد تا وضعیت بازنگری شود و دامنه یا صفحات دوباره در نتایج ظاهر شوند.
Algorithmic Penalty
الگوریتمهای خودکار گوگل، مانند Panda یا SpamBrain، رفتارهای غیرطبیعی را شناسایی میکنند و بهصورت خودکار جریمهای اعمال مینمایند. این جریمه معمولاً باعث کاهش شدید رتبه میشود؛ سقوط رتبه میتواند بین ۳۰ تا ۸۰ درصد باشد. پس از اصلاح محتوا و حذف تمام تکنیکهای Cloaking، باید صبر کرد تا الگوریتم بازنگری شود؛ این بازنگری معمولاً در بازهٔ ۲ تا ۴ هفته اتفاق میافتد.
De‑indexing
در موارد شدید، گوگل میتواند URL یا حتی کل دامنه را از فهرست نتایج حذف کند (De‑indexing). در این حالت، سایت هیچ بازدید ارگانیکای دریافت نمیکند. برای بازگرداندن این وضعیت، ابتدا باید تخلف را بهطور کامل رفع کرد، سپس درخواست بازنگری ارسال شود. معمولاً تا ۳۰ روز زمان میبرد تا گوگل پس از بررسی درخواست، دوباره دامنه یا URL را در فهرست نتایج بگنجاند.
۶.۲. پیامدهای قانونی
در برخی حوزههای قضایی، ارائهٔ محتوای گمراهکننده میتواند بهعنوان تخلف تجاری یا تبلیغاتی شناخته شود و عواقب قانونی داشته باشد.
– اتحادیه اروپا (GDPR): اگر محتوای گمراهکننده منجر به جمعآوری دادههای شخصی شود، ممکن است تحت قوانین حفاظت دادهها (GDPR) بررسی شود. این میتواند منجر به جریمههای مالی، دستورهای اصلاحی یا حتی ممنوعیت پردازش دادهها برای سازمان باشد.
– ایالات متحده (FTC): کمیسیون تجارت فدرال (FTC) بهطور فعال بهدنبال تبلیغات گمراهکننده میگردد. اگر یک وبسایت با استفاده از Cloaking اطلاعات نادرست یا گمراهکنندهای به کاربران ارائه دهد، FTC میتواند اقدام قانونی، جریمههای مالی و دستورهای اصلاحی علیه صاحب سایت اعمال کند.
بهطور کلی، علاوه بر خطرات سئو، استفاده از Cloaking میتواند بهعنوان تخلف قانونی در نظر گرفته شود و منجر به هزینههای مالی، خسارت به اعتبار برند و حتی دعاوی قضایی شود. بنابراین، توصیه میشود که همیشه از روشهای شفاف و مطابق با راهنماییهای موتورهای جستجو برای بهبود سئو استفاده کنید.
۷. راهکارهای جایگزین برای بهبود سئو بدون Cloaking
۷.۱. بهینهسازی محتوا (On‑Page SEO)
- تحقیق کلیدواژه: از ابزارهایی مثل Google Keyword Planner, Ahrefs, SEMrush برای شناسایی کلیدواژههای مرتبط با نیت کاربر استفاده کنید.
- ساختار محتوا:
– عنوان (H1) شامل کلیدواژه اصلی.
– زیرعنوانها (H2/H3) برای تقسیمبندی منطقی.
– پاراگرافهای کوتاه، لیستهای بولتدار و جداول (در صورت نیاز) برای خوانایی.
- متا تگها:
– Meta Title ≤ 60 کاراکتر، شامل کلیدواژه.
– Meta Description ≤ 160 کاراکتر، توصیف جذاب و شامل کلیدواژه.
- بهینهسازی تصاویر: استفاده از alt‑text توصیفی، فشردهسازی (WebP) و ابعاد مناسب.
۷.۲. بهبود تجربه کاربری (UX)
– سرعت بارگذاری: استفاده از lazy loading, فشردهسازی CSS/JS, CDN.
– طراحی واکنشگرا: اطمینان از نمایش صحیح در تمام دستگاهها.
– قابلیت دسترسی (Accessibility): استفاده از ARIA labels، رنگهای کنتراستدار.
۷.۳. لینکسازی طبیعی (Off‑Page SEO)
– تولید محتوای ارزشمند: مقالات طولانی، راهنماهای گامبه‑گام، اینفوگرافیکها.
– بازاریابی محتوا: انتشار در شبکههای اجتماعی، خبرنامهها، مشارکت در انجمنهای تخصصی.
– دریافت بکلینکهای معتبر: از طریق guest posting، پیشنهاد منابع، یا پرسش و پاسخ در سایتهای معتبر.
۷.۴. استفاده از Structured Data (Schema.org)
– افزودن JSON‑LD برای مقالات، محصولات، FAQها، رویدادها و … به موتورهای جستجو کمک میکند تا محتوای صفحه را بهتر درک کنند و در نتایج غنی (Rich Snippets) نمایش دهند.
۷.۵. بهکارگیری تکنیکهای A/B Testing بهجای Cloaking
بهجای نمایش محتوای متفاوت به رباتها، میتوانید نسخههای مختلف صفحه را برای کاربران واقعی تست کنید و بر پایهٔ دادههای واقعی (CTR, Conversion) تصمیم بگیرید. این کار کاملاً شفاف و مطابق با راهنماییهای گوگل است.
۸. گامهای عملی برای شناسایی و حذف Cloaking از سایت خود
- بررسی لاگهای سرور
– بهدنبال درخواستهای با *User‑Agent*های شناختهشده (Googlebot, Bingbot) بگردید.
– مقایسهٔ پاسخهای HTTP (کد وضعیت 200 vs 301/302) و محتوای بازگشتی.
- استفاده از ابزارهای Crawl Simulation
– در Screaming Frog, یک Crawl جدید ایجاد کنید و *User‑Agent* را به `Googlebot` تغییر دهید. سپس یک Crawl دیگر با *User‑Agent* پیشفرض مرورگر انجام دهید. خروجیها را مقایسه کنید.
- بررسی متا تگها و محتوا
– اطمینان حاصل کنید که متا تگها (title, description) برای همهٔ User‑Agentها یکسان هستند.
- حذف یا اصلاح قوانین .htaccess
– اگر در فایل `.htaccess` شرطی برای IP یا User‑Agent وجود دارد، آن را حذف یا بهروزرسانی کنید.
- بازنگری کدهای سرور (PHP/Node/ASP)
– بهدنبال توابعی مانند `$_SERVER[‘HTTP_USER_AGENT’]`, `$_SERVER[‘REMOTE_ADDR’]` بگردید که برای تصمیمگیری دربارهٔ محتوای خروجی استفاده میشوند.
- ارسال درخواست بازنگری به Google
– پس از حذف تمام موارد Cloaking، به Google Search Console → Manual Actions بروید و درخواست بازنگری (Reconsideration Request) را ارسال کنید. در درخواست، توضیح دهید که چه تغییراتی اعمال شده و چگونه از این بهبعد بهصورت شفاف سئو میکنید.
۹. مثال عملی: تبدیل یک صفحهٔ Cloaked به صفحهٔ سئو‑محافظتشده
۹.۱. وضعیت اولیه (Cloaked)
<?php
$userAgent = $_SERVER['HTTP_USER_AGENT'];
if (strpos($userAgent, 'Googlebot') !== false) {
// محتوای بهینهشده برای ربات
echo "<h1>خرید بهترین لپتاپهای 2025</h1>";
echo "<p>قیمت ویژه، تخفیف 30٪، ارسال رایگان.</p>";
} else {
// محتوای عادی برای کاربر
echo "<h1>صفحهٔ خطا</h1>";
echo "<p>متأسفیم، این صفحه در دسترس نیست.</p>";
}
?>
۹.۲. تبدیل به صفحهٔ شفاف
<?php
// حذف تمام شرطها، نمایش یکسان برای همه
$title = "خرید لپتاپهای 2025 – بهترین قیمت و تخفیف";
$description = "مقایسه مدلهای مختلف لپتاپ، بررسیهای تخصصی، تخفیفهای ویژه و ارسال رایگان.";
?>
<!DOCTYPE html>
<html lang="fa">
<head>
<meta charset="UTF-8">
<title><?= $title ?></title>
<meta name="description" content="<?= $description ?>">
<!-- Structured Data -->
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Product",
"name": "لپتاپ 2025 مدل X",
"offers": {
"@type": "Offer",
"priceCurrency": "IRR",
"price": "25000000",
"availability": "https://schema.org/InStock",
"url": "https://example.com/product/x"
}
}
</script>
</head>
<body>
<h1>لپتاپهای 2025 – مقایسه و خرید</h1>
<p>در این صفحه میتوانید مدلهای مختلف را مقایسه کنید، نظرات کاربران را بخوانید و با تخفیفهای ویژه خرید کنید.</p>
<!-- محتوای واقعی، جدول مقایسه، نظرات، دکمهٔ خرید -->
</body>
</html>
نتیجه: تمام کاربران، از جمله رباتهای گوگل، همان محتوا را میبینند؛ هیچگونه فریبی وجود ندارد و سئو بهصورت طبیعی بهبود مییابد.
۱۰. نکات کلیدی برای حفظ سئو سالم در طولانیمدت
۱. شفافیت
سئو موفق بر پایهٔ این اصل است که رباتهای موتورهای جستجو و کاربران انسانی دقیقاً همان محتوای یکسان را دریافت کنند. هر گونه تفاوت عمده—مثلاً نمایش متن یا لینکهای مخفی فقط برای رباتها—بهسرعت توسط الگوریتمهای تشخیص تقلب شناسایی میشود و منجر به جریمه میشود. برای حفظ شفافیت:
– تمام عناوین صفحه (`<title>`)، توضیحات متا (`<meta name=”description”>`) و دادههای ساختاری (Schema.org) را برای همهٔ User‑Agentها یکسان نگه دارید.
– از شرطهای سروری که بر پایهٔ IP، User‑Agent یا سایر متغیرها محتوای متفاوتی میسازند، خودداری کنید.
– پیش از انتشار هر تغییر، با ابزارهای شبیهساز خزیدن (مانند Screaming Frog یا Sitebulb) درخواستها را با User‑Agentهای مختلف بفرستید و خروجی را مقایسه کنید.
۲. پایش مستمر
سئو یک فرآیند پویاست؛ برای اطمینان از عدم بروز مشکلات، بهصورت دورهای موارد زیر را بررسی کنید:
– لاگهای سرور: بهدنبال درخواستهای غیرعادی باشید؛ مثلاً IPهای ناشناخته یا User‑Agentهای غیرمعمول که ممکن است نشانگر تلاش برای Cloaking باشند.
– Google Search Console – URL Inspection: این ابزار به شما نشان میدهد که گوگل چه محتوایی برای هر URL میگیرد. اگر با محتوای نمایش دادهشده برای کاربر متفاوت باشد، هشدار دریافت میکنید.
– Core Web Vitals: سرعت بارگذاری، تعامل و پایداری صفحه را مانیتور کنید. تغییرات ناگهانی در این معیارها میتواند نشانگر مشکلات فنی یا تغییرات غیرمجاز باشد.
– رتبه کلمات کلیدی: هر گونه افت ناگهانی در رتبه میتواند نشانهٔ جریمه یا مشکل فنی باشد؛ بهصورت ماهانه یا دو ماه یکبار رتبهها را بررسی کنید.
یک تقویم ماهانه تنظیم کنید تا در هر ماه حداقل یک بار این موارد را مرور کنید.
۳. بهروزرسانی منظم محتوا
محتواهای قدیمی یا منسوخ میتوانند ارزش سئوی سایت را کاهش دهند. برای حفظ ارزش افزوده برای کاربر:
– هر ۲‑۳ ماه یکبار مطالب را بازنگری کنید؛ اطلاعاتی که دیگر صحیح نیستند را حذف یا بهروز کنید.
– بخشهای پر بازدید را با دادههای جدید، آمار بهروز یا نکات عملی تکمیل کنید.
– در صورت افزودن بخشهای جدید، از کلمات کلیدی مرتبط استفاده کنید و ساختار منطقی (H2، H3) را حفظ کنید.
۴. استفاده از ابزارهای کیفیت
بهکارگیری ابزارهای تخصصی به شما کمک میکند تا مشکلات فنی را پیش از تأثیر بر سئو شناسایی کنید:
– PageSpeed Insights برای بهینهسازی سرعت بارگذاری و شناسایی منابع سنگین.
– Mobile‑Friendly Test برای اطمینان از سازگاری صفحه با دستگاههای موبایل.
– Chrome DevTools برای بررسی عملکرد JavaScript، رندرینگ و دسترسی (Accessibility).
بهروز نگه داشتن این ابزارها و اجرای توصیههای آنها باعث بهبود تجربه کاربری و در نتیجه ارتقای سئو میشود.
۵. اجتناب از تکنیکهای مخفی
هر گونه استفاده از CSS یا HTML برای مخفی کردن متن یا لینکهای مهم (مانند `display:none`، `visibility:hidden` یا `opacity:0`) میتواند توسط موتورهای جستجو بهعنوان Cloaking تشخیص داده شود. بهجای این روشها:
– اگر محتوایی برای کاربران خاص (مثلاً نسخهٔ موبایل) نیاز است، از طراحی واکنشگرا (Responsive Design) یا طراحی سازگار (Adaptive Design) استفاده کنید؛ این روشها در چارچوب قوانین سئو قرار دارند.
– برای نمایش اطلاعات تکمیلی، از عناصر تعاملی مانند تبها یا آکاردئونها استفاده کنید که برای رباتها نیز قابل دسترسی هستند (محتوا در HTML اصلی باقی میماند).
۶. مستند کردن تغییرات
هر تغییر اساسی در ساختار URL، ناوبری یا محتوای صفحه باید ثبت شود. یک Change Log یا فایل مستندات داخلی میتواند شامل موارد زیر باشد:
– تاریخ تغییر، توضیح مختصر، شخص مسئول.
– URLهای تحت تأثیر، تغییرات در متا تگها یا دادههای ساختاری.
– نتایج تستهای پیشانتشار (مثلاً خروجیهای URL Inspection).
این مستندات در زمان درخواست بازنگری به گوگل یا بررسی داخلی تیم سئو بسیار مفید هستند.
جمعبندی
حفظ سئو سالم در طولانیمدت نیازمند ترکیبی از شفافیت کامل، پایش مستمر، بهروزرسانی منظم محتوا، استفاده از ابزارهای کیفیت، اجتناب از تکنیکهای مخفی و مستند کردن دقیق تغییرات است. با رعایت این اصول، سایت شما نه تنها در برابر جریمههای الگوریتمی و قانونی محافظت میشود، بلکه تجربه کاربری بهبود مییابد و رتبههای ارگانیک بهصورت پایدار رشد میکند.
۱۱. پرسشهای متداول (FAQ) درباره Cloaking
۱. آیا میتوانم برای کاربران موبایل محتوای متفاوتی نسبت به دسکتاپ ارائه دهم؟
بله، این کار بهعنوان *Responsive Design* یا *Adaptive Design* شناخته میشود و در صورتی که برای رباتها همان محتوا نمایش داده شود، خلاف قوانین نیست. هدف اصلی ممنوعیت، تفاوت بین ربات و کاربر انسانی است، نه بین دستگاههای مختلف.
۲. اگر فقط برای تست داخلی از Cloaking استفاده کنم، آیا جریمه میشود؟
اگر تست فقط در محیط محلی یا سرورهای تست باشد و هیچگاه به اینترنت عمومی (و بهویژه به رباتهای موتورهای جستجو) دسترسی نداشته باشد، جریمهای اعمال نمیشود. اما اگر تست روی دامنهٔ زنده باشد و رباتها به آن دسترسی پیدا کنند، خطر جریمه وجود دارد.
۳. آیا استفاده از CDN که بهصورت خودکار محتوا را کش میکند میتواند Cloaking باشد؟
خیر، مگر اینکه CDN بهطور خاص بر اساس IP یا User‑Agent محتوای متفاوتی ارائه دهد. کش معمولی که همان محتوا را برای همه کاربران سرو میکند، مشکلی ایجاد نمیکند.
۴. آیا میتوانم از Cloaking برای نمایش نسخهٔ ترجمهشدهٔ صفحه به رباتهای بینالمللی استفاده کنم؟
نه. اگر رباتهای مختلف (مثلاً Googlebot‑en، Googlebot‑fa) بهصورت متفاوت محتوا دریافت کنند، این نیز بهعنوان Cloaking محسوب میشود. بهتر است از تگهای `hreflang` برای اعلام نسخههای زبانی استفاده کنید.
۵. چه زمانی باید درخواست بازنگری (Reconsideration Request) به گوگل بفرستم؟
پس از حذف کامل تمام موارد Cloaking، بهصورت کامل تست کنید که رباتها همان محتوای عمومی را دریافت میکنند. سپس از طریق Google Search Console → Manual Actions → Reconsideration Request یک پیام واضح (حدود 200‑300 کلمه) ارسال کنید که شامل:
– توضیح دقیق مشکل (Cloaking)
– گامهای انجامشده برای رفع آن (حذف کدهای شرطی، بهروزرسانی .htaccess، تست با ابزارهای مختلف)
– تعهد به رعایت راهنماییهای گوگل در آینده
۱۲. جمعبندی نهایی
Cloaking، اگرچه در کوتاهمدت میتواند نتایج جذابی بدهد، اما بهعنوان یک تکنیک مخفی و فریبکارانه، خطرات جدی برای هر وبسایتی دارد: جریمههای الگوریتمی، حذف از نتایج جستجو، کاهش اعتبار دامنه و حتی پیامدهای قانونی.
بهجای این روش، تمرکز بر روی بهینهسازی شفاف، تجربه کاربری عالی، لینکسازی طبیعی و استفاده از دادههای ساختاری است. این استراتژیها نه تنها در طولانیمدت رتبهٔ پایدار و رشد ارگانیک را تضمین میکنند، بلکه از خطرات جریمههای ناخواسته جلوگیری میسازند.
اگر در حال حاضر وبسایت شما شامل هرگونه کد یا تنظیمات شرطی برای نمایش محتوای متفاوت به رباتهاست، هماناکنون اقدام به حذف آن کنید، لاگها و ابزارهای تست را بهکار بگیرید و پس از اطمینان از شفافیت کامل، درخواست بازنگری به گوگل ارسال کنید.



قوانین ارسال دیدگاه
لطفاً در ارسال دیدگاه از کلمات مناسب استفاده کنید. ارسال اسپم ممنوع است.