
مقدمه
طراحی سایت بهعنوان اولین گام برای حضور آنلاین هر برند، بستر اصلی برای اجرای استراتژیهای بهینهسازی سئو است؛ بدون ساختار فنی مناسب، حتی بهترین محتواها نیز در نتایج جستجو نادیده میمانند. در این پاراگراف، به نقش کلیدی ترکیب طراحی سایت با اصول سئو میپردازیم و نشان میدهیم که چگونه سرعت بارگذاری، ساختار URL و تجربه کاربری میتوانند بهعنوان عوامل رتبهبندی در موتورهای جستجو عمل کنند. همچنین، اهمیت تولید محتوا را بهعنوان پلی میان ظاهر زیبا و عملکرد فنی بررسی میکنیم؛ محتوای منحصربهفرد نه تنها بازدیدکنندگان را جذب میکند، بلکه سیگنالهای ارزشمندی به الگوریتمهای گوگل میفرستد که به بهبود موقعیت صفحات کمک میکند.
بهینهسازی سئو فراتر از انتخاب کلمات کلید است؛ این فرآیند شامل بهبود ساختار داخلی سایت، استفاده صحیح از تگهای متا، بهینهسازی تصاویر و پیادهسازی دادههای ساختاریافته میشود. در کنار این موارد، تولید محتوا نقش تکمیلی دارد؛ مقالات، پستهای وبلاگ و توضیحات محصول باید بهصورت منظم و با کیفیت بالا ارائه شوند تا بازدیدکنندگان زمان بیشتری در سایت بگذرانند و نرخ پرش کاهش یابد. ترکیب هوشمندانهٔ طراحی سایت، بهینهسازی سئو و تولید محتوا نه تنها باعث افزایش ترافیک ارگانیک میشود، بلکه تجربه کاربری بهتری را فراهم میآورد و در نهایت منجر به تبدیل بازدیدکنندگان به مشتریان وفادار میگردد.

محتوای تکراری (Duplicate Content) چیست؟
محتوای تکراری به هر متنی گفته میشود که بهصورت کامل یا جزئی در دو یا چند صفحهٔ وبسایت (یا حتی در وبسایتهای مختلف) ظاهر میشود و توسط موتورهای جستجو بهعنوان یک نسخهٔ یکسان شناسایی میشود. این پدیده میتواند به دلایل فنی، استراتژیک یا اشتباهات انسانی رخ دهد و تأثیرات متعددی بر سئو، تجربهٔ کاربری و اعتبار سایت دارد.
۱. انواع محتواهای تکراری
۱.۱ تکرار داخلی (Internal Duplicate)
در این حالت همان متن یا ساختار در چند URL داخل یک دامنهٔ واحد منتشر میشود. دلایل رایج شامل استفاده از پارامترهای URL برای فیلتر کردن محتوا، نسخههای چاپی یا موبایلی صفحه، یا تنظیمات نادرست ریدایرکتهاست. برای مثال، یک صفحهٔ «قوانین» ممکن است هم بهصورت `example.com/terms` و هم بهصورت `example.com/terms-of-use` در دسترس باشد؛ در نتیجه موتورهای جستجو نمیدانند کدام نسخه را ایندکس کنند.
۱.۲ تکرار خارجی (External Duplicate)
متن یکسان در دامنههای مختلف منتشر میشود. این اتفاق معمولاً زمانی رخ میدهد که وبسایتها محتوا را بدون اجازه کپی میکنند، یا وقتی که یک شرکت چند وبسایت تحت مالکیت یکسان دارد و همان مقاله را در همهٔ آنها منتشر میکند. اگرچه در برخی موارد (مانند انتشار خبر توسط چند خبرگزاری) این کار طبیعی است، اما اگر بیش از حد تکرار شود میتواند به کاهش اعتبار هر دو منبع منجر شود.
۱.۳ محتواهای شبهتکراری (Near‑duplicate)
در این حالت متنها تقریباً مشابه هستند؛ ممکن است جملات یا پاراگرافها جابجا یا کمی تغییر داده شوند، اما معنای کلی یکسان باقی میماند. ابزارهای تشخیص محتوا (مانند الگوریتمهای شبیهسازی Cosine یا Jaccard) معمولاً این نوع محتوا را بهعنوان تکرار شناسایی میکنند. مثال رایج، صفحات محصول با توصیفهای بسیار مشابه برای محصولات مختلف است که تنها نام یا شمارهٔ مدل تغییر میکند.
۲. دلایل بروز محتواهای تکراری
- پارامترهای URL: افزودن پارامترهای پیگیری (UTM) یا فیلترهای جستجو به URL بدون استفاده از canonical باعث ایجاد نسخههای متعدد میشود.
- سیستم مدیریت محتوا (CMS): برخی CMSها بهصورت پیشفرض نسخههای چاپی یا AMP را تولید میکنند که URLهای متفاوتی دارند.
- پستهای چندزبانه: اگر ترجمهها بهصورت جداگانه ایجاد شوند اما محتوای اصلی را کپی کنند، ممکن است محتوای تکراری در همان زبان ایجاد شود.
- کپیبرداری از وبسایتهای دیگر: برای سئو یا پر کردن محتوا، برخی وبسایتها متنهای دیگران را بدون تغییر میگذارند.
- صفحات خطای 404 یا 301 نادرست: وقتی صفحهای حذف میشود اما ریدایرکت به صفحهٔ دیگری که محتوا مشابه دارد تنظیم میشود، میتواند تکرار ایجاد کند.
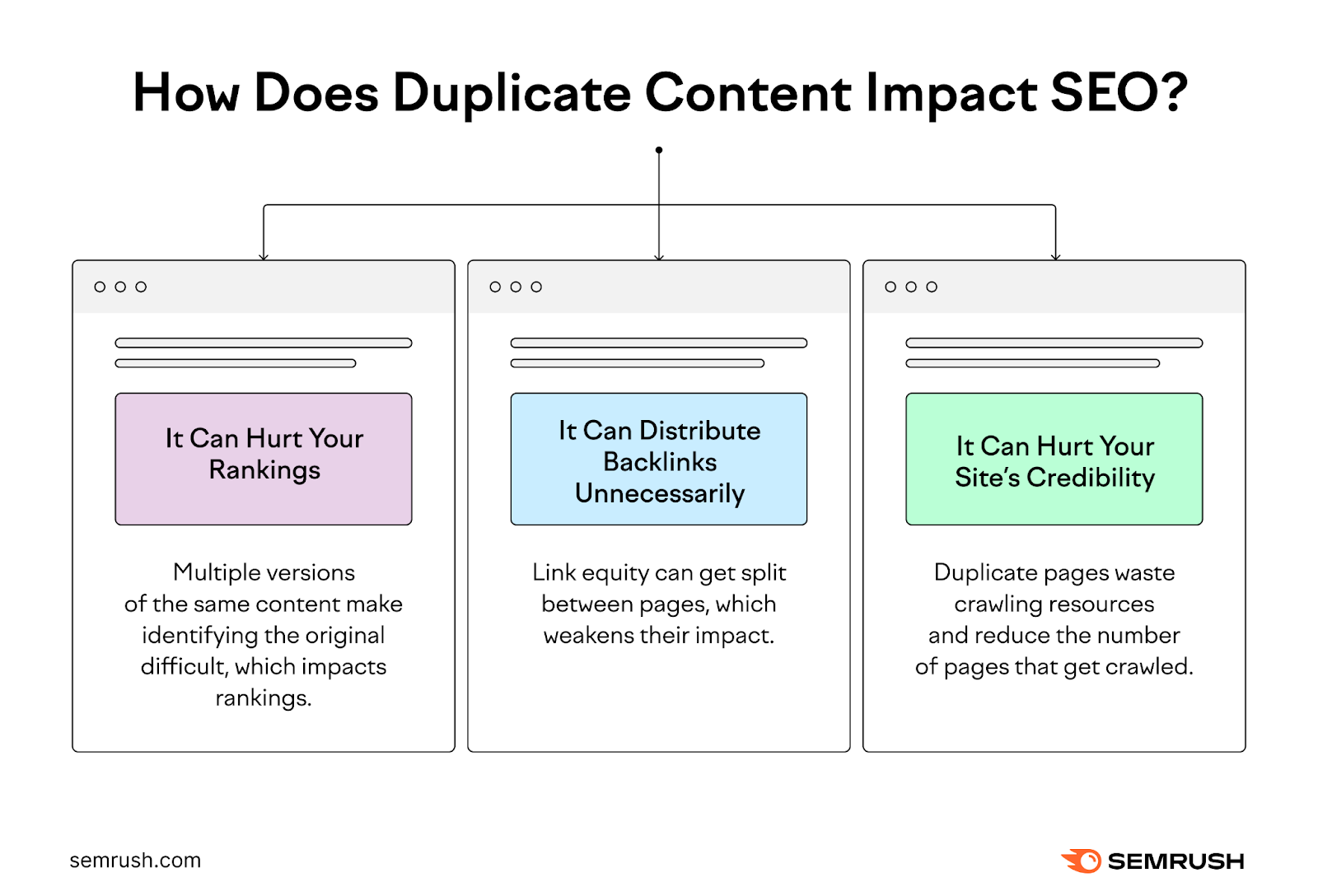
۳. تأثیرات محتواهای تکراری بر سئو
۳.۱ ایندکسگذاری و رتبهبندی
موتورهای جستجو سعی میکنند تنها یک نسخهٔ اصلی (canonical) را ایندکس کنند. اگر چندین نسخه وجود داشته باشد، ممکن است «نمرهٔ لینک» (link equity) بین آنها تقسیم شود و هر صفحه نتواند بهصورت کامل قدرت رتبهبندی خود را نشان دهد. در بدترین حالت، تمام نسخهها نادیده گرفته میشوند و هیچکدام در نتایج ظاهر نمیشوند.
۳.۲ تجربهٔ کاربری
کاربران ممکن است بهصورت تصادفی به صفحهای با محتوای مشابه هدایت شوند، که باعث سردرگمی و کاهش رضایت میشود. این موضوع میتواند نرخ پرش (bounce rate) را افزایش دهد و سیگنالهای منفی برای الگوریتمهای جستجو ایجاد کند.
۳.۳ هزینهٔ خزیدن (Crawl Budget)
اگر رباتهای گوگل زمان زیادی را صرف کشف نسخههای تکراری کنند، زمان کمتری برای کشف صفحات جدید یا بهروزرسانی محتواهای مهم باقی میماند. این میتواند بهخصوص در سایتهای بزرگ مشکلساز باشد.
۴. روشهای شناسایی محتواهای تکراری
- Google Search Console – در بخش “Coverage” یا “HTML Improvements” میتوانید URLهای گزارششده بهعنوان تکراری را ببینید.
- ابزارهای سئو – Screaming Frog، Sitebulb یا Ahrefs قابلیت کشف صفحات با محتوای مشابه را دارند.
- دستورات site: – با جستجوی `site:example.com “متن خاص”` میتوانید صفحات حاوی همان متن را پیدا کنید.
- بررسی لاگ سرور – الگوهای درخواستهای مکرر به URLهای مشابه میتواند نشانگر مشکل باشد.
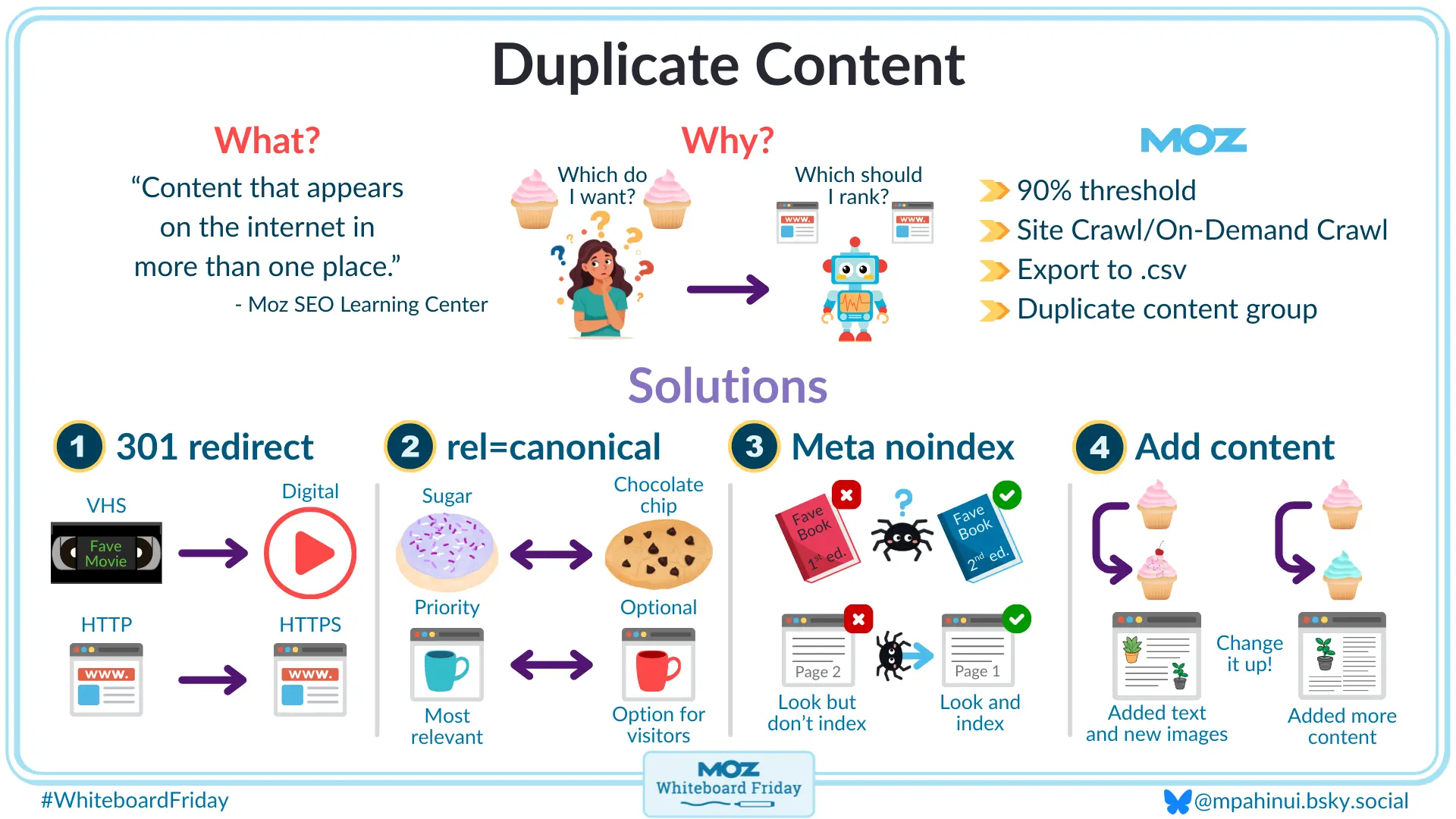
۵. راهکارهای رفع و پیشگیری
۵.۱ استفاده از تگ canonical
در هر صفحهٔ تکراری، تگ `<link rel=”canonical” href=”URL-اصلی”>` را قرار دهید تا موتورهای جستجو بدانند کدام نسخه باید ایندکس شود.
۵.۲ تنظیم ریدایرکت 301
اگر صفحهای منسوخ یا ترکیب شده است، با ریدایرکت 301 به نسخهٔ اصلی هدایت کنید. این کار نه تنها لینکاکوئیتی را حفظ میکند، بلکه از بروز نسخههای تکراری جلوگیری میکند.
۵.۳ حذف یا ترکیب محتوا
در مواردی که محتواهای تکراری ارزش افزوده ندارند، بهتر است یکی از آنها را حذف یا بهصورت یک مقالهٔ جامع ترکیب کنید.
۵.۴ پارامترهای URL را مدیریت کنید
در Google Search Console میتوانید پارامترهای URL را تعریف کنید تا رباتها از ایندکسگذاری نسخههای پارامتری خودداری کنند. همچنین میتوانید از URLهای تمیز (clean) استفاده کنید و پارامترهای ردیابی را پس از کلیک حذف کنید.
۵.۵ استفاده از متا تگ noindex
برای صفحات کمارزش یا تکراری که نمیخواهید ایندکس شوند، میتوانید متا تگ `noindex, follow` را اضافه کنید. این کار باعث میشود رباتها صفحه را بخوانند اما در نتایج جستجو نمایش ندهند.
۵.۶ بهینهسازی ساختار CMS
در سیستمهای مدیریت محتوا، تنظیمات مربوط به نسخههای چاپی، AMP یا صفحات موبایلی را بررسی کنید و اطمینان حاصل کنید که هر نسخه دارای تگ canonical مناسب است.
۶. مثالهای عملی
مثال ۱: پارامترهای UTM
یک صفحهٔ محصول با URL زیر وجود دارد:
https://example.com/product/123?utm_source=google&utm_medium=cpc
اگر این URL بدون canonical بهعنوان نسخهٔ جدیدی شناخته شود، گوگل ممکن است دو نسخه (با و بدون پارامتر) را ایندکس کند. راهحل: افزودن تگ canonical به URL پایه (`https://example.com/product/123`) و تنظیم پارامترهای UTM در Google Search Console بهعنوان “Ignore”.
مثال ۲: صفحات چاپی
یک مقالهٔ وبلاگی بهصورت زیر در دسترس است:
– نسخهٔ وب: `https://example.com/blog/seo-tips`
– نسخهٔ چاپی: `https://example.com/blog/seo-tips/print`
اگر هر دو بدون canonical باشند، محتوا تکراری محسوب میشود. راهحل: در صفحهٔ چاپی تگ canonical به نسخهٔ وب اضافه کنید.
مثال ۳: محتواهای شبهتکراری در فروشگاههای بزرگ
یک فروشگاه آنلاین ۱۰۰۰ محصول دارد که توصیفهای آنها تنها با تغییر نام محصول متفاوت است. این توصیفها بهصورت شبهتکراری شناخته میشوند و میتوانند بهعنوان «thin content» توسط گوگل penalized شوند. راهحل: ایجاد توصیفهای منحصر بهفرد برای هر محصول یا ترکیب توصیفهای عمومی با ویژگیهای خاص هر محصول.
۷. نکات کلیدی برای جلوگیری طولانیمدت
– نقشهٔ سایت (XML Sitemap) را بهروز نگه دارید و فقط URLهای اصلی را در آن بگنجانید.
– پروتکلهای URL (http vs https، www vs non‑www) را یکپارچه کنید و از ریدایرکت 301 دائمی برای تمام نسخههای غیرمستقیم به نسخهٔ اصلی استفاده کنید. این کار باعث میشود تنها یک URL معتبر در ایندکس باقی بماند.
– برچسبهای hreflang را برای صفحات چندزبانه بهدرستی تنظیم کنید؛ در غیر این صورت موتورهای جستجو ممکن است نسخههای زبانهای مختلف را بهعنوان تکرار در نظر بگیرند.
– پیشنهادات خودکار CMS را بررسی کنید؛ برخی افزونهها یا قالبها بهصورت پیشفرض نسخههای AMP یا صفحهٔ چاپی را تولید میکنند. اطمینان حاصل کنید که برای هر یک تگ canonical به نسخهٔ اصلی اشاره دارد.
– نظارت دورهای: هر ۲‑۳ ماه یک اسکن کامل سایت با ابزارهای Screaming Frog یا Sitebulb انجام دهید تا URLهای تکراری یا بدون canonical شناسایی شوند.
– آموزش تیم محتوا: نویسندگان و ویراستاران را دربارهٔ اهمیت تولید محتوای منحصر بهفرد و اجتناب از کپیبرداری مستقیم آموزش دهید. استفاده از چکلیستهای پیشنویس (مانند “آیا این متن قبلاً در سایت منتشر شده است؟”) میتواند خطاهای انسانی را کاهش دهد.
– استفاده از متادیتای ساختاریافته: افزودن schema.org (مانند `Article` یا `Product`) به صفحات اصلی کمک میکند تا موتورهای جستجو بهتر تشخیص دهند کدام نسخه باید بهعنوان منبع اصلی در نظر گرفته شود.
– بهروزرسانی لینکهای داخلی: اطمینان حاصل کنید که تمام لینکهای داخلی به URLهای canonical اشاره میکنند؛ این کار نه تنها از بروز تکرار جلوگیری میکند، بلکه ارزش لینکاکوئیتی را بهصورت مؤثرتر توزیع مینماید.
جمعبندی
محتوای تکراری میتواند بهصورت داخلی یا خارجی، کامل یا شبهتکراری ظاهر شود و اثرات منفی بر ایندکسگذاری، رتبهبندی، تجربهٔ کاربری و هزینهٔ خزیدن داشته باشد. با استفاده از تگ canonical، ریدایرکت 301، حذف یا ترکیب محتواهای غیرضروری، مدیریت پارامترهای URL و نظارت منظم میتوانید این مشکل را بهطور مؤثر کنترل کنید و سئوی سایت خود را بهینه نگه دارید.



قوانین ارسال دیدگاه
لطفاً در ارسال دیدگاه از کلمات مناسب استفاده کنید. ارسال اسپم ممنوع است.